

By Saad Ahmad, Executive Vice President of Smart IS International
Overview
JDA/BY WMS requires customers to have a data archival strategy. The approach that they push and most customers end up adopting is akin to using a sledge hammer to push a nail.
The JDA/BY approach is quite interesting and probably an appropriate mechanism if the year was 1995. Their approach is to say that the data will be archived to an identical environment from the point of view of software but that other environment will have older data. This is a very interesting paradigm because all of the reports, queries, use cases, etc. that we may have will work in exactly the same way in the archive environment — all we have to validate is that the data from the current system is properly moved to the archive instance.
Issues
So what is the issue with above approach?
- We are adding another environment to support. So lets say we have 5 production environments (for sets of warehouses) — we really need 5 additional environments for archive. Then to support testing and development we will have 10s of additional environments. If we have some related environments like EMS, parcel, report writer, etc — those may be needed as well.
- These additional environments need to be part of the software development life cycle. All roll-outs need to go to these environments as well.
- We create “cut off” points, i.e. some queries would need to go to multiple environments.
- Some advanced use cases like “recalling” and “returns” may need overly complex solutions where we may need to query archive and online instances.
- An additional point of failure for daily maintenance.
What are my Options?
So do we have any options? First we really need to check the calendar. What we considered as “too much data” in 1995 will be considered a “below average database size” today. Secondly we need to understand that number of rows in a table does not cause an issues — it is the access path. Thirdly, today’s databases have advanced features like partitioning that render such complex strategies obsolete. In this article, I will focus on solutions available in Oracle — but please note that SQLServer has similar concepts and features.
First, let us firmly establish the problem we are trying to solve. The size of the table is not a measure of performance — it is always the access path — so what we are really trying to address is data management not performance. Another “problem” that archiving solution supposedly addresses is that queries against the archive instance will not adversely impact the online system’s performance.
Data Management- Partitioning
The solution that is most promising for data management problem is to utilize advanced database feature for “partitioning” and let the data stay in the online system. This implies that your single online instance will have all of the data all the time. Dispatched shipments will simply be in a different partition.
Ideal partitioning solution will be to create the main partition by range (or in new versions interval partitions). Then have a sub-partition by warehouse. That will result in manageable data in each partition. This partitioning strategy provides good information to the database to parallelize queries.
Data Isolation- Reporting Database
The other problem of providing an isolated environment for queries is easily addressed by utilizing the concept of stand-by database or “data guard” or “reporting databases”. Please refer to the database documentation — but what it provides is a completely isolated database instance that is “almost” up to date and can be used for reporting. The setup is low level DBA activity and requires little application support. But this may not be needed for majority of the scenarios. Such a database should be made available for true research activities where we will not be using the JDA/BY client to access the tables. All use cases where we need to access the data through application should be handled by connecting to the online instance and letting database handle the large amounts of data.
How should I partition the data?
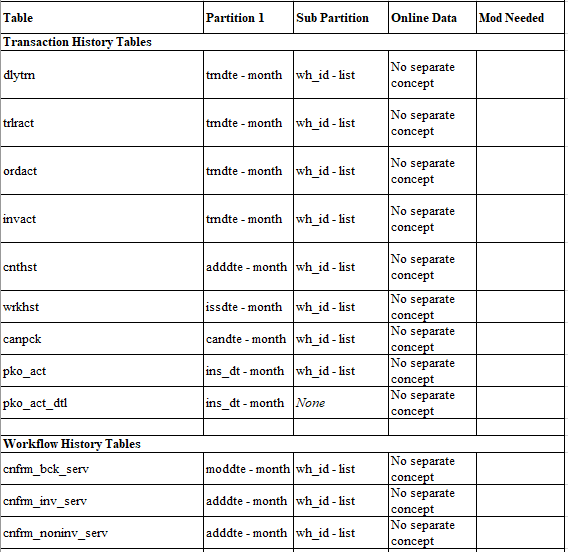
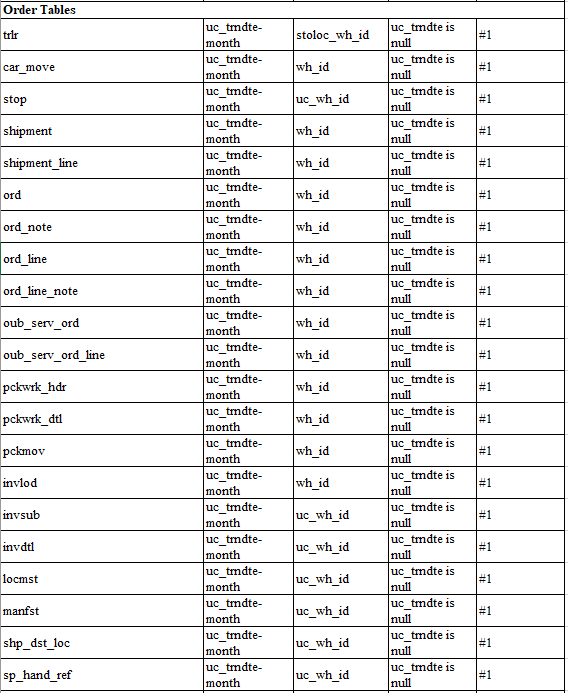
To effectively partition we need to have a good date column on the table and for warehouse sub-partition warehouse id should be in the table. Unfortunately, some tables in JDA/BY WMS do not have these columns so small modifications are needed to make it all come together.
In the following section I have listed the tables and suitable partitioning keys. Following enhancements should be done to make it all work:
- When “shipping trailer” dispatches, update following tables with uc_trndte set to dispatch date/time. And if table does not have a warehouse id, then we set uc_wh_id column.
- trlr
- car_move
- stop
- shipment
- shipment_line
- ord
- ord_note
- ord_line
- ord_line_note
- oub_serv_ord
- oub_serv_ord_line
- pckwrk_hdr
- pckwrk_dtl
- pckmov
- invlod
- invsub
- invdtl
- locmst
- manfst
- shp_dst_loc
- sp_hand_ref
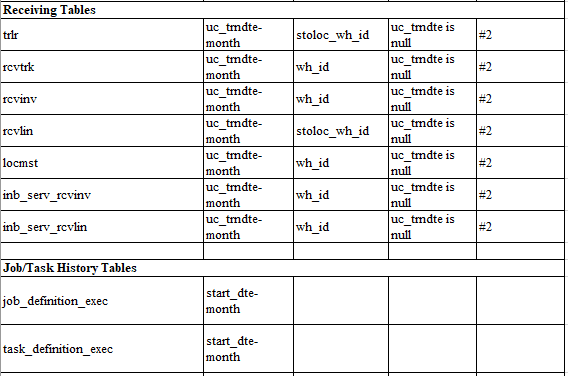
2. When “receiving trailer” dispatches, update following tables with uc_trndte set to dispatch date/time. And if table does not have a warehouse id, then we set uc_wh_id column.
- trlr
- rcvtrk
- rcvinv
- rcvlin
- locmst
- inb_serv_rcvinv
- inb_serv_rcvlin
3. As a general rule — use base 36 sequences
So the overall partitioning strategy will end up as follows (not including work order tables)
Conclusion
If you have been live for some time — chances are you have experienced your share of Archiving Blues. Because of the overly complex archive solution — people often resent even going to archive instance. Volumes of priceless data in dlytrn is completely ignored and rather than valuing it we consider it a burden. Using the simple strategies described here we can enter the 21st century for our JDA/BY WMS systems. We can consider dlytrn as a valuable data source which we choose to not purge and are not worried about it growing to 100s of millions of rows. We can utilize simple techniques like “stand-by databases” and mine through that data to see what gems may be there — or if we do not have time or budget right now at least we can leave data there rather than losing it. Also by keeping it all in one system where historical data is easily accessible we do not have to worry about untimely exceptions. If we have to print a packing slip from 5 years ago — no problem; we simply go to “Report Operations” and print it.
Originally published on saadwmsblog.blogspot.com




